The most important shift I made on this project was moving from thinking about research as studying a product to thinking about research as building evaluation infrastructure. When the product is an agentic AI system that changes with every model update, one-time studies aren't enough. You need frameworks — codebooks, pipelines, rubrics — that can assess quality continuously as the product evolves.
The shelf-stable CUJs and memory principles, and personalization principles I co-created were the most impactful artifact I built here, not just because it answered a research question, but because it gave the entire team a shared definition of "good" — one that engineering could implement, product could prioritize against, and researchers could evaluate consistently. That's the kind of infrastructure that outlasts any individual study.
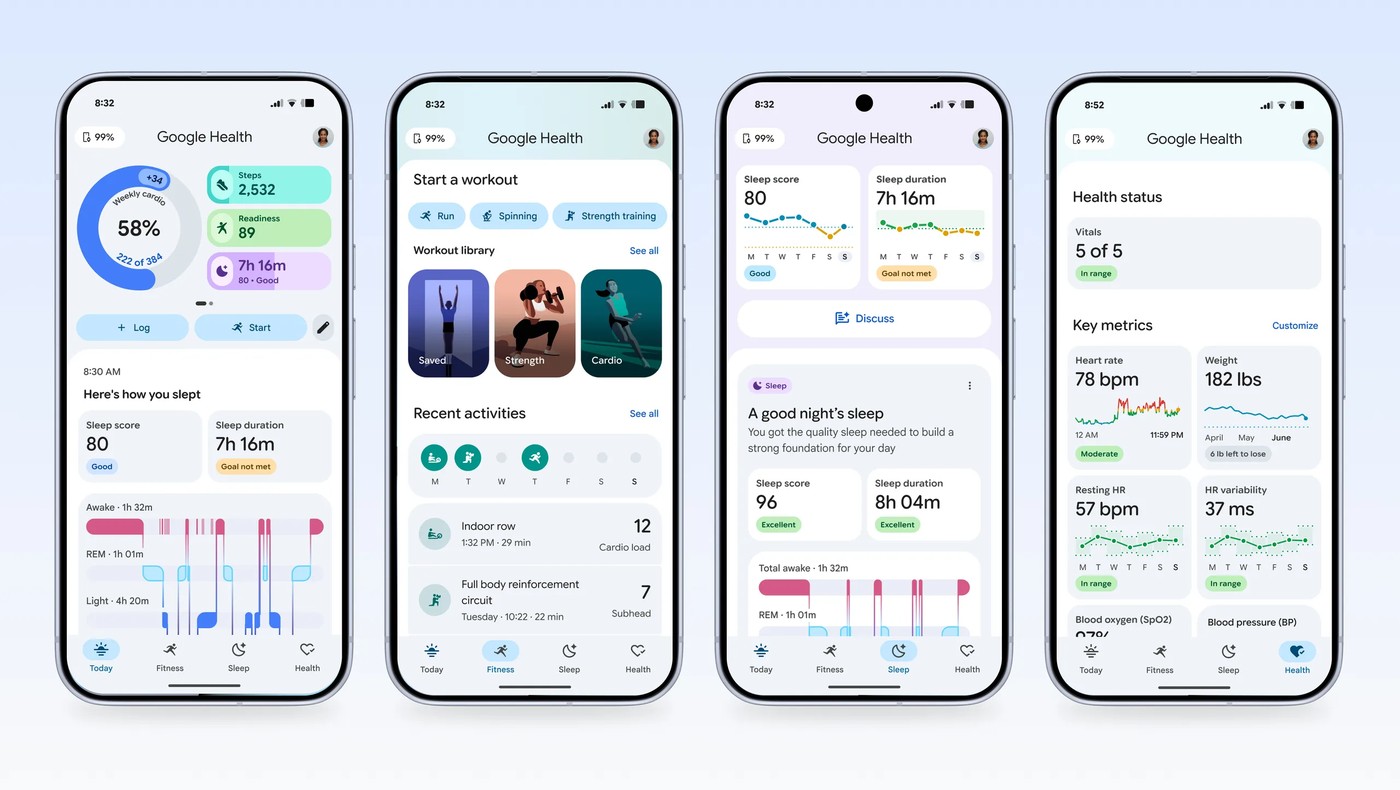
The other lesson: in a health app, trust is not a feature. It's the precondition for everything else. Users didn't engage with the Health Coach's capabilities until they trusted it wouldn't mislead them. Research's job was to find exactly where and why that trust broke, the dynamics involved for different user segments, and to fix it before launch.